大数据时代下计算机数据处理系统的挑战与演进
随着信息技术的飞速发展,大数据已成为驱动社会进步和产业变革的核心力量。海量、多样、高速、低价值密度的数据特性,对传统的计算机数据处理系统提出了前所未有的严峻挑战。这些挑战不仅涉及硬件架构、存储技术、计算范式,更深入到软件设计、算法优化乃至整个系统生态的层面。
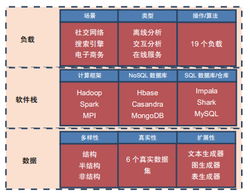
在数据存储与管理方面,传统的关系型数据库在面对TB乃至PB级别的非结构化或半结构化数据时,显得力不从心。大数据的体量超出了单机存储的物理极限,其多样性(如文本、图像、视频、日志流)要求系统具备灵活的数据模型。这催生了分布式文件系统(如HDFS)和NoSQL数据库(如HBase、MongoDB)的兴起,它们通过横向扩展和牺牲部分一致性(遵循BASE原则)来获得高可用性与可扩展性。这也带来了数据一致性、分区容错性以及跨系统数据整合的新难题。
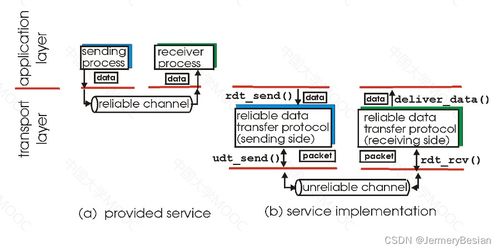
在计算模式与处理能力上,批处理框架(如Hadoop MapReduce)虽然能处理海量历史数据,但其高延迟特性无法满足实时或近实时分析的需求。因此,流计算框架(如Apache Flink、Spark Streaming)应运而生,它们需要在数据持续流入的同时进行即时处理,这对系统的吞吐量、低延迟和精确的状态管理提出了极高要求。复杂的数据挖掘与机器学习任务需要迭代计算,这对基于磁盘I/O的MapReduce模式构成了瓶颈,促使了基于内存计算的Spark等框架的发展。计算从集中式向分布式、从批处理向流批一体的融合演进,是应对大数据高速性(Velocity)的必然选择。
在系统架构与资源调度层面,大数据处理往往需要在由成千上万台普通服务器组成的集群上运行。如何高效、公平地调度CPU、内存、网络和IO资源,确保众多并发的数据处理任务稳定、高效地执行,是一大核心挑战。YARN、Kubernetes等资源管理与调度平台的出现,旨在解耦计算框架与资源管理,提升集群利用率和运维效率。但异构硬件(如GPU、FPGA)的集成、混部作业的隔离性以及跨数据中心调度等问题仍在持续探索中。
数据质量、安全与隐私保护也是大数据处理中不可忽视的挑战。原始数据常常包含大量噪声、不一致和缺失值,需要在处理流程中嵌入数据清洗和质量管控环节。与此数据集中存储与分析增加了隐私泄露和遭受攻击的风险。如何在保证数据分析效用的前提下,通过差分隐私、联邦学习、可信执行环境等技术实现数据的安全合规使用,是系统设计必须融入的考量。
从开发与运维视角看,大数据系统的复杂性急剧增加。技术栈繁多(存储、计算、调度、监控),组件间耦合与依赖关系复杂,使得系统开发、测试、部署和故障诊断的难度呈指数级增长。对运维人员的技能要求也从单一的节点管理,转向对整个分布式系统状态洞察和自动化运维的能力。
大数据对计算机数据处理系统的挑战是全方位的。它正推动着计算体系结构从中心化走向分布式协同,处理范式从批量走向实时智能,设计目标从单纯追求性能扩展到兼顾可扩展性、容错性、安全性与易用性。应对这些挑战的过程,也正是计算机技术不断自我革新和突破的过程。随着边缘计算、人工智能与大数据处理的进一步融合,一个更智能、更自适应、更一体化的数据处理系统新范式正在孕育之中。
最新产品