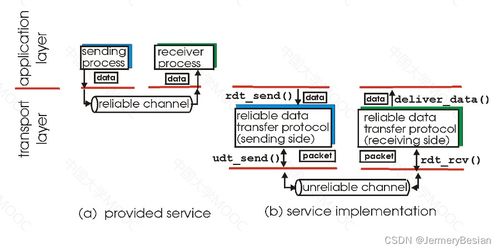
计算机数据的符号与大小限制 探秘数字世界的基石
计算机是现代社会的核心引擎,它处理着海量的信息。当我们深入探究其内部运作时,会发现一些看似基础却至关重要的概念,比如数据的“有无符号”以及“大小限制”。理解这些概念,不仅有助于我们更好地使用计算机,也能让我们窥见数字世界的基本法则。
数据的“符号”:有符号与无符号
在计算机中,数据是以二进制形式存储的,即由0和1组成的序列。数据的“符号”属性,决定了我们如何解释这些二进制序列所代表的数值。
1. 无符号数据
无符号数据,顾名思义,就是没有正负之分的数值。它只能表示非负数(零和正数)。计算机为无符号数分配一段固定长度的内存(比如8位、16位、32位、64位),所有的二进制位都用于表示数值的大小。
- 优点:在相同的位数下,无符号数能表示的最大正数比有符号数更大。例如,一个8位的无符号数能表示的范围是0到255(2^8 - 1)。
- 应用场景:非常适合表示那些天然非负的量,如内存地址、数组索引、像素颜色值(如RGB中的0-255)、物品数量、年龄等。
2. 有符号数据
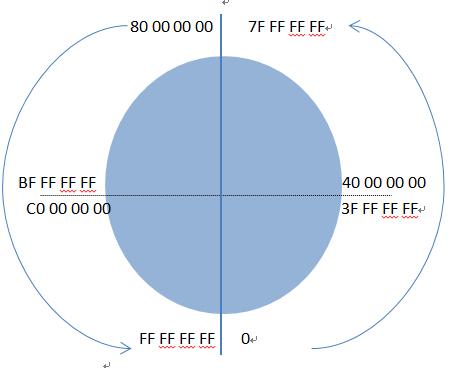
有符号数据则可以表示正数、负数和零。为了区分正负,计算机需要占用一个二进制位来作为“符号位”。最常见的表示法是“二进制补码”。在补码表示法中,最高位(最左边的一位)为符号位:0代表正数,1代表负数。其余位表示数值的绝对值(但编码方式与无符号数不同,负数采用补码形式)。
- 优点:能够直接表示正负,符合现实世界中许多有方向或对立概念的需求。
- 应用场景:广泛用于需要正负值的计算,如温度(零上/零下)、财务收支(收入/支出)、坐标位移、科学计算等。
核心区别:对于同一段二进制序列,解释为有符号数还是无符号数,会得到完全不同的十进制值。例如,二进制11110000,如果作为8位无符号数解释,是240;如果作为8位有符号数(补码)解释,则是-16。因此,编程时必须明确数据的类型,否则会导致逻辑错误。
数据处理的大小限制:为何存在?
你是否遇到过“整数溢出”错误,或者试图上传一个超大文件时被提示“文件过大”?这些现象都源于计算机数据处理的内在限制。主要原因有以下几点:
1. 硬件层面的物理限制:有限的存储单元
计算机的所有数据都存储在由晶体管等物理元件构成的内存和寄存器中。每个存储单元(如一个内存位)的物理尺寸和制造成本决定了计算机不可能拥有“无限大”的存储空间。CPU设计时,会定义其处理数据的基本单位,称为“字长”(如32位、64位)。一次操作能处理的数据位数是固定的。例如,一个32位CPU,其通用寄存器通常是32位宽,这意味着它一次性能进行运算的整数最大值受32位二进制数的表示范围限制。
2. 性能与效率的权衡
固定大小的数据单元带来了巨大的效率优势。CPU的运算电路(如加法器)是针对特定位宽优化设计的,处理固定长度的数据速度极快。如果允许数据的位数无限增长,那么每一次算术运算都需要动态检查数据长度并分配资源,其开销将变得无法忍受,计算速度会急剧下降。固定位宽使得硬件设计简单、高效且成本可控。
3. 地址空间的限制
这个限制尤其体现在内存访问上。内存中的每个字节都有一个唯一的地址。CPU通过地址总线来指定要访问的内存位置。如果地址总线的位数是n,那么CPU最多能寻址2^n个不同的内存单元。这就是为什么32位系统最大只支持约4GB内存(2^32字节),而64位系统的寻址能力则大得多,目前几乎是无限的。
4. 软件与标准的约定
为了确保不同系统、不同编程语言之间的兼容性和可移植性,业界制定了各种数据类型的标准(如C语言中的int、long,IEEE 754浮点数标准)。这些标准明确了各种数据类型所占的位数和表示范围,程序员在此框架下编写程序,从而保证程序行为的可预测性。
影响与应对
这些限制直接影响了编程和系统设计:
- 溢出(Overflow):当运算结果超出了数据类型所能表示的范围时,就会发生溢出,导致结果错误(例如,两个很大的正数相加可能得到一个负数)。
- 精度损失:对于浮点数,表示范围和精度之间存在权衡。极大或极小的数,或者进行连续运算时,可能会丢失精度。
- 大数处理:当需要处理超过基本数据类型范围的整数(如加密学中的超大素数)或超高精度小数时,需要借助特殊的软件库(如GNU MP库)或编程语言特性(如Python的任意精度整数),用算法和额外的内存来模拟大数运算,但这会牺牲速度。
结论
计算机中数据的“有符号/无符号”属性,是信息编码的一种基本选择,它赋予了二进制位现实世界的意义。而数据处理的大小限制,则是计算机作为物理实体和工程产物所必须面对的客观约束,是效率、成本、兼容性多方权衡的结果。
正是这些看似“限制”的规则,构成了计算机稳定、高效运行的基石。随着技术进步(如从32位到64位架构的迁移),这些限制的边界在不断拓展,但“有限性”这一本质不会改变。理解并妥善处理这些限制,是每一位软件开发者和系统设计者的必备素养,也是我们驾驭数字巨兽的关键所在。
最新产品