数据处理分布式计算设计概要
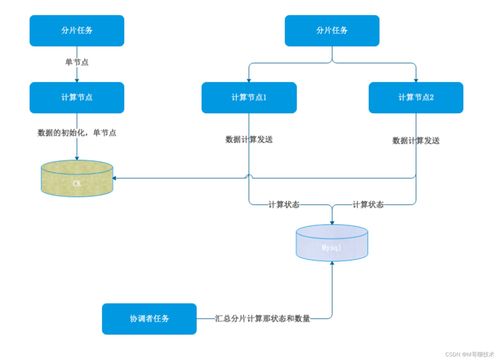
随着数据量的爆炸式增长和业务复杂度的不断提升,传统的集中式数据处理架构已难以满足高并发、低延迟、海量数据存储与计算的需求。分布式计算技术应运而生,成为现代数据处理系统的核心支撑。本文旨在概述数据处理分布式计算系统的设计关键要素,为构建高效、可靠、可扩展的数据处理平台提供概要性指引。
一、 核心设计目标
一个优秀的数据处理分布式计算系统设计,应围绕以下几个核心目标展开:
- 高可扩展性:系统应能通过简单地增加计算或存储节点,线性或近似线性地提升整体处理能力与容量,以应对未来数据规模的增长。
- 高容错性与可靠性:单个或多个节点故障不应导致服务中断或数据丢失。系统需具备故障自动检测、恢复与数据冗余机制。
- 高吞吐与低延迟:能够并行处理大规模数据任务,在可接受的时间内完成计算,满足实时或准实时分析的需求。
- 易于编程与管理:提供简洁的编程模型和接口,降低开发分布式应用的复杂性。具备完善的监控、调度和运维管理工具。
- 资源高效利用:能够智能调度任务,均衡集群负载,最大化硬件资源的利用率。
二、 核心架构组件
典型的分布式数据处理系统通常包含以下关键组件:
- 分布式存储层:
- 功能:提供海量、可靠、高可用的数据存储基础。数据通常被分片(Sharding)存储在多个节点上。
- 代表性技术:HDFS(Hadoop Distributed File System)、对象存储(如AWS S3、阿里云OSS)、分布式数据库(如HBase、Cassandra)等。
- 资源管理与调度层:
- 功能:作为集群的“操作系统”,统一管理所有计算节点(CPU、内存、磁盘、网络)的资源,并按需分配给上层计算框架。
- 代表性技术:YARN(Yet Another Resource Negotiator)、Kubernetes、Mesos等。
- 分布式计算引擎层:
- 功能:执行具体的计算逻辑。根据数据处理模式的不同,可分为批处理、流处理和交互式查询等引擎。
- 代表性技术:
- 批处理:MapReduce(基础模型)、Apache Spark(内存计算,性能更优)。
- 流处理:Apache Flink、Apache Storm、Spark Streaming。
- 交互式查询:Apache Hive、Presto、Impala。
- 协调与服务发现层:
- 功能:在分布式环境中维护配置信息、命名服务、分布式同步和集群成员管理,是保证系统一致性的关键。
- 代表性技术:Apache ZooKeeper、etcd等。
三、 关键设计模式与考量
- 数据分区与分布:合理的数据分区策略(如范围分区、哈希分区)是并行计算效率的基础,需尽量保证数据均匀分布,并减少计算过程中的数据移动(Shuffle)。
- 计算模型:
- MapReduce:经典的“分而治之”模型,适合离线批处理,但I/O开销较大。
- DAG(有向无环图)模型:如Spark、Flink采用,将计算任务表示为一系列阶段的依赖关系,允许更灵活的优化(如流水线执行),显著提升性能。
- 容错机制:
- 数据容错:通过多副本(Replication)或纠删码(Erasure Coding)技术保证数据的持久性。
- 计算容错:采用检查点(Checkpointing)和阶段重算(Stage Re-computation)或 lineage(血统)信息重新计算丢失的数据。
- 任务调度策略:调度器需考虑数据本地性(将任务调度到数据所在的节点)、资源公平性、任务优先级等因素,以优化整体执行效率。
- 一致性模型:根据应用场景,在强一致性、最终一致性等模型间做出权衡。例如,实时计费系统需要强一致性,而一些统计报表场景可接受最终一致性。
四、 技术选型与实践挑战
在实际设计中,技术选型需紧密结合业务场景:
- 离线大数据分析:可选用 Hadoop (HDFS+YARN+MapReduce/Hive) 或 Spark 生态栈。
- 实时数据流处理:Flink 因其低延迟和高吞吐的流处理能力成为主流选择。
- 混合负载(Lambda/Kappa架构):可能需要整合批处理和流处理两套引擎,或采用像 Spark Structured Streaming、Flink 这样能统一批流处理的框架。
面临的挑战包括:
- 集群规模扩大后的性能线性增长瓶颈。
- 复杂环境下的故障诊断与调试困难。
- 数据安全与隐私保护的挑战。
- 跨地域多数据中心部署带来的网络延迟与数据同步问题。
五、 与展望
分布式计算是处理当今海量数据的基石。一个成功的设计始于清晰的核心目标,并依赖于分层、解耦的稳固架构。随着云原生、Serverless 计算和人工智能的融合,未来分布式数据处理系统将更加智能化、自动化和弹性化,例如计算与存储的进一步分离、基于Kubernetes的弹性调度、以及利用AI进行自动性能调优等。设计者需要持续关注技术演进,在稳定性、性能与成本之间找到最佳平衡点,以支撑不断发展的数据驱动型业务。
最新产品

2018年大数据智能搜索专业课题项目 计算机数据处理的创新与实践
Python从零到数据分析与可视化 终极保姆级全流程指南
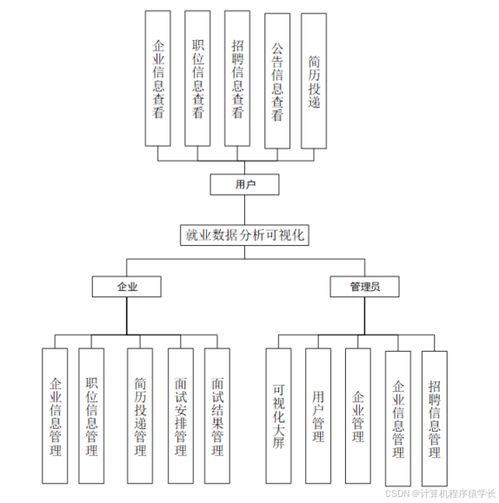
基于Python的河南省大学生就业数据分析与可视化系统设计与实现

计算机在转动惯量实验数据处理中的应用
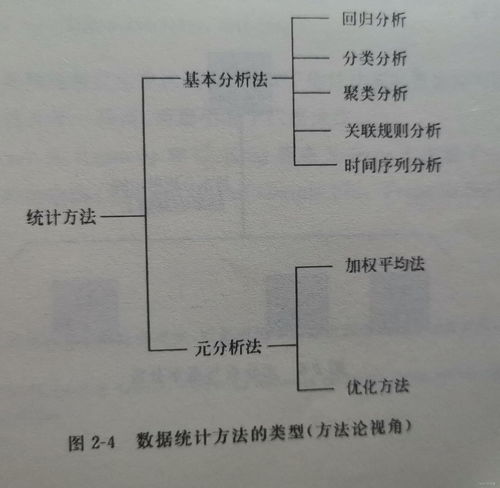
大数据概率理论基础 构建海量数据处理的数学核心
赋能工业未来 FUXA携手ARMxy嵌入式计算机,打造数字化转型可视化解决方案
智能编班工具 计算机数据处理在教育管理中的革新应用
SSM家校服务及数据分析系统 构建智慧教育新生态
计算机专业热门就业方向解析 聚焦数据处理
python数据处理 欧统局年度就业和活动数据 报告和详细代码 代码附在最后 sklearn线性回归预测